
polecenia zarządzania procesami i filtry
Polecenia:
*Polecenie ps generuje liste wszystkich aktywnych procesow w systemie, ich stan, rozmiar, nazwe oraz właściciela. Istnieje bardzo dużo opcji tego polecenia, najwazniejsze opisze. Najczesciej ustawianym parametrem polecenia ps jest -auxww. Ten parametr wyswietla wszystkie procesy (bez wzgledu na to, czy kontroluja one terminal), wlasciciala kazdego procesu oraz wszystkie parametry procesu.
-a - wyswietla wszystkie procesy posiadajace terminal kontrolny, nie tylko bieżące procesy uzytkowników.
-r - wyswietla tylko pracujace procesy.
-x - wyswietla procesy nie posiadajace terminala kontrolnego.
-u - wyswietla wlasciciali procesow.
-f - wyswietla powiazania miedzy procesami - format drzewiasty.
-l - generuje liste w dlugim formacie.
-w - wyswietla parametry lini polecen procesu (do polowy linii).
-ww - wyswietla wszystkie parametry lini polecen procesu niezaleznie od dlugosci.
-j - format prac: pgid sid.
-s - format sygnalu.
-m - wyswietla informacje o pamieci.
-S - dodaj czas cpu potomka i bledy stron.
-h - bez naglówka.
-n - wyjscie numeryczne dla USER i WCHAN.
-txx - tylko procesy z kontrolujacym tty XX; dla xx mozesz uzyc zarówno nazwy urzadzenia z "/dev", jak i tej nazwy z dopuszczalnym od?upaniem tty lub cu. Jest to odwrócona heurystyka, której ps uzywa do wydrukowania skróconych nazw tty w polu TT, np. ps -t1.
W pierwszej lini znajduja sie naglowki informacyjne o znaczeniu kolejnych kolumn wydruku:
USER - kto jest wlascicielem danego procesu.
PID - numer identyfikacyjny procesu.
%CPU - procentowe wykozystanie procesora.
%MEM - procentowe wykazystanie pamieci przez proces.
VSZ - wielkosc pamieci wirtualnej przydzielonej procesowi.
RSS - wielkosc rzeczywistej pamieci wykorzystywanej przez proces.
TTY - terminal kontrolny procesu. ? w tej kolumnie oznacza, ze proces nie jest polaczony z zadnym terminalem kontrolnym.
STAT - stan prosesu:
S - proces jest uspiony. Wszystkie procesy, ktore sa gotowe do uruchomienia (lecz procesor jest zajety czyms innym) zostana uspione.
R - proces jest aktualnie wykonywany.
D - proces jest uspiony, oczekuje na operacje ( zazwyczaj I/O ).
T - proces jest debuggowany lub zostal zatrzymany.
Z - zombie. Oznacza, ze albo proces macierzysty nie potwierdzil smierci procesu potomnego lub proces macierzysty zostal niewlasciwie zabity i dopukie nie zostanie kompletnie zabity, proces init nie bedzie mogl kozystac z procesu potomnego.
START - czas lub data rozpoczecia procesu.
TIME - przedzial czasu wykorzystany przez CPU.
COMMAND - nazwa procesu oraz jego parametry.
*Aby zabic jakis proces nalezy posluzyc sie programem kill. Generalnym przeznaczeniem tego programu jest wyslanie sygnalow do uruchomionych procesow. Skladnia polecenia jest nastepujaca (gdzie -n okresla numer sygnalu):
kill -n PID lub kill -v nazwa_procesu
Najwazniejsze sygnaly to:
-1 - (hang up) zawies.
-9 - (kill) zabij.
-15 - wstrzymaj proces.
-v nazwa_procesu - zabije proces po podaniu jego nazwy
Jesli wydamy polecenie kill PID (PID mozemy odczytac z ps lub top ) to do procesu zostanie wyslany sygnal -15.
*Funkcja wait wstrzymuje proces wywolujacy do momentu, az jeden z procesow potomnych przestanie dzialac. Jezeli zakonczony potomek juz jest, to funkcja wraca natychmiast.
Implementacja funkcji wait jest funkcja systemowa sys_wait4, Funkcje ta wywoluje inna funkcja systemowa - sys_waitpid, a ta zas funkcja sys_wait.
Parametrem funkcji wait jest wskaznik do zmiennej typu int. Wywolanie wait(s) odpowiada wywolaniu sys_wait4(-1,s,0,NULL). Pod adres s funkcja ma wpisac przyczyne zakonczenia procesu.
Procesy brane pod uwage
Funkcja wait poszukujac procesu potomnego, ktory przestal dzialac rozpatruje procesy ZOMBIE i STOPPED.
ZOMBIE
Proces moze osiagnac ten stan na dwa sposoby. Pierwszy z nich to wywolanie funkcji exit.Jedna z czynnosci wykonywanych w tej funkcji jest zapamietanie argumentu (czyli kodu wyjscia) w polu exit_code struktury task_structodpowiadajacej konczacemu sie procesowi. Scislej rzecz biorac zapamietywane jest 8 najmlodszych bitow argumentu przesunietych o osiem pozycji w lewo.
Dla wielu sygnalow czynnoscia domyslna jest zakonczenie procesu. Jesli proces nie zmieni obslugi takiego sygnalu i otrzyma go, to wtedy rowniez przechodzi w stan ZOMBIE, o czym mozemy sie przekonac analizujac funkcje systemowado_signal, Do pola exit_code jest wtedy wpisywany numer sygnalu (ewentualnie ze znacznikiem pamieci), ktory przyniosl procesowi smierc. Numer ten nie jest przesuwany tak jak argument funkcji exit.
Wspomniany znacznik pamieci to siodmy bit liczac od zera. Jest ustawiany, jesli konczacy sie proces generuje plik core, czyli zrzut pamieci wewnetrznej. Dzieje sie tak przy standardowej obsludze sygnalow SIGQUIT,SIGILL,SIGTRAP, SIGABRT, SIGFPE i SIGSEGV (dotyczy dostarczonego Linuxa 2.0, Stevens podaje jeszcze inne sygnaly dla systemow 4.3BSD i V).
STOPPED
Proces przechodzi w stan STOPPED po otrzymaniu sygnalu SIGSTOP, SIGTSTP, SIGTTIN, SIGTTOU (2 ostatnie nie wystepuja w systemie V). Uprzednio numer sygnalu, ktory zatrzymal proces jest wpisywany do pola exit_code. Ojciec przy przegladaniu swoich synow w funkcji wait w przypadku procesu STOPPED sprawdza, czy w tym polu jest zero. Jesli nie, to wait zwraca identyfikator znalezionego procesu wczesniej wyzerowawszy to pole0. Jesli tak, to znaczy, ze ojciec juz sie dowiedzial o zatrzymaniu procesu potomnego i nie ma sensu informowac go o tym powtornie. Wtedy przeszukiwanie jest kontynuowane.
*W tym wypadku z pomocą przychodzi nam polecenie nohup, którego zadaniem jest utrzymanie procesu przy życiu, nawet po wylogowani się użytkownika. Czyli jest to dokładnie to czego szukamy. Jak powinno wyglądać wywołanie?
[1] 8879
$ nohup: zignorowanie wejścia i dołączenie wyników do `nohup.out'
Tym sposobem nasz dowolnySkrypt.sh będzie działał w tle systemu jako demon. Powyższy output omówi nam również, że logi z programu w postaci treści wyrzucanych na strumień standardowego wyjścia, będą zapisywane do pliku nohump.out. Oczywiście możemy to dowolnie modyfikować i zapisywać logi czy to do innego pliku, czy zupełnie je zignorować przekierowując je na urządzenie /dev/null.
*Polecenie sleep opóźnia działanie wybranych akcji (np. przerwa pomiędzy działaniem poszczególnych poleceń w skrypcie).
Polecenie nie posiada żadnych opcji, poza dwoma standardowymi: --help, --version. Składnia polecenia wygląda następująco:
Gdzie:
- liczba - liczba sekund opóźnienia. Liczba ta może być całkowitą, bądź rzeczywistą wartością.
- suffix - precyzowanie w jakich jednostkach czasu ma być określona pauza (podajemy bez nawiasów kwadratowych), dostępne:
- s - sekunda, standardowo, nawet bez podawania sufiksu
- m - minuta
- h - godzina
- d - dzień
Jeśli podamy w poleceniu 2 liczby, to łączny czas opóźnienia będzie sumą 2 liczb. Poniższe rysunki pokazują użycie.

Rys 1. Pauza na 2 sekundy.

Rys 2. Pauza na 3 sekundy.

Rys 3. Pauza na 2 minuty.
Jak widać na rysunku 2, liczby można łączyć, i ich suma to będzie łączny czas pauzy. Po skończeniu się czasu przerwy terminal wyświetli nową linię i polecenia będzie można wpisywać dalej.
* nice – komenda systemu Unix, służąca do uruchamiania procesów z określonym priorytetem.
Opis działania:
Komenda ustala priorytet procesu w algorytmie szeregowania, zgodnie z zasadą, że procesowi o większym priorytecie zostanie przyznane więcej czasu procesora niż procesowi o mniejszym priorytecie. Priorytet określa się parametrem zwanym niceness, będącym liczbą całkowitą z przedziału -20 (najwyższy priorytet) do 19 (najniższy priorytet). Tylko użytkownik o uprawnieniach superusera może używać ujemnych wartości parametru niceness, ale w Linuxie poprzez edycję pliku /etc/security/limits.conf, można to umożliwić innym użytkownikom i grupom[1]. Procesy uruchamiane bez użycia komendy nice mają domyślnie priorytetu równy 0, ale administrator systemu może to zmienić.
Dokładny matematyczny efekt ustawienia danej wartości niceness dla procesu zależy od szczegółów działania algorytmu szeregowania w danej implementacji systemu. Zwykle algorytmy szeregowania posiadają różne heurystyki, np. do faworyzowania procesów ograniczonych przez operacje wejścia/wyjścia nad procesami ograniczonymi przez jednostkę centralną. Dla przykładu, gdy dwa identyczne procesy są uruchomione równolegle na jednordzeniowym systemie, przydział czasu procesora do każdego z nich będzie proporcjonalny do  , gdzie p jest wartością priorytetu procesu. Dlatego proces uruchomiony z wartością niceness równą 15 otrzyma
, gdzie p jest wartością priorytetu procesu. Dlatego proces uruchomiony z wartością niceness równą 15 otrzyma 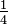 czasu procesora przydzielonego procesowi o normalnym priorytecie, zgodnie ze wzorem
czasu procesora przydzielonego procesowi o normalnym priorytecie, zgodnie ze wzorem  . Z drugiej strony w algorytmie szeregowania zaimplementowanym w BSD 4.x, stosunek dla tego samego czasu wyniesie
. Z drugiej strony w algorytmie szeregowania zaimplementowanym w BSD 4.x, stosunek dla tego samego czasu wyniesie  .
.
Powiązany program renice może być użyty do zmiany priorytetu procesu który jest już uruchomiony. Linux posiada także program ionice, używany do zmiany priorytetu procesów na podstawie operacji wejścia/wyjścia.
Składnia wywołania:
Opcje:
--helpWyświetla informację o stosowaniu programu i dostępnych opcjach, kończy działanie.
-n adjustment, -adjustment, --adjustment=adjustmentwartość będąca liczbą całkowitą z przedziału -20 (najwyższy priorytet) do 19 (najniższy priorytet). Wartości ujemne, powodujące zwiększenie priotytetu, mogą być używane tylko przez użytkowników uprzywilejowanych. Jeśli nie zostanie podana żadna wartość, domyślnie zostanie ona ustawiona na 10.
--versionWyświetla numer wersji programu i kończy działanie.
*O większości poleceń shella można myśleć jako o filtrach, tak jak przedstawiono to na rysunku poniżej:

Polecenie ma jedno wejście nazywane wejściem standardowym (standard input skrót stdin), za pomocą którego przyjmowana jest informacja wejściowa znak po znaku. Wyjścia są dwa: standardowe wyjście podstawowe (standard output, skrót stdout) oraz standardowe wyjście błędów (standard error skrót stderr). Każde polecenie filtruje dane ze standardowego wejścia, przetwarza je w specyficzny sposób, i przekazuje na standardowe wyjście. Domyślnym strumieniem danych wejściowych jest klawiatura. Natomiast dane wyjściowe i komunikaty o błędach są przekazywane na ekran. Trzy liczby które widzimy na rysunku 0 , 1 , 2 są zarezerwowane i odpowiadają trzem plikom które są zawsze uruchamiane w momencie egzekucji polecenia:
stdin - strumień danych z klawiatury terminale czyli dane wejściowe → 0
stdout – strumień danych wysyłany na ekran terminala czyli dane wyjściowe → 1
stderr - strumień znaków informujących o błędach → 2
Które z poleceń Linuxa możemy zaliczyć do filtrów ? Czym jest filtr ? Jest on poleceniem, które wykonuje pewno działanie na plikach zawierających tekst. Rezultat tego działania , który jest także tekstem, wyświetlany jest na ekranie (chociaż nie tylko). Powiązanie między sobą wielu filtrów (czyli jednoczesna egzekucja kilku poleceń) jest możliwa dzięki użyciu metody zwanej przekierowaniem lub innej metody nazywanej „potokiem” (patrz rozdział potoki).
Jako filtry traktować będziemy polecenia, które:
→ podlegają mechanizmowi wejścia/wyjścia standardowego
→ pobierają strumień danych zawsze z wejścia standardowego, przetwarzają dane i wysyłają je na wyjście standardowe, natomiast komunikaty o błędach zostają przez polecenie przekierowane do wyjścia błędów
→ oczekują na wejście prostego strumienia znaków i ten strumień znaków po przetworzeniu wysyłają na standardowe wyjście.
Z tej definicji wynika, że polecenie who cal czy ls nie są filtrami. Z punktu widzenia pracy użytkownika Linuxa, filtry służą przede wszystkim do operowania na plikach testowych i w połączeniu z mechanizmem potoków tworzą niezwykle wydajne a zarazem proste narzędzie.